RL, GAN, and RLHF for Language Models
Dive into the early history of reinforcement learning for language models

Reinforcement learning is a framework to train an agent that mimics human’s learning process by – observing the environment and the status, attempting an action, receiving a reward, and adjusting our behavior according to the received feedback.
Here is a framework of the whole process.
 Robot icons created by Freepik - Flaticon
Environment icons created by iconixar - Flaticon
Robot icons created by Freepik - Flaticon
Environment icons created by iconixar - Flaticon
Let’s get to language models (the LLM or large language models are using the same formula). Language models are an abstracted statistical model of how humans use language in the real world. Researchers have proposed multiple methods to more efficiently and accurately find the representative patterns in the real world language data. One most often used formulas in language models is an autoregressive function:
Where x is a word (more accurately is called a token) in a piece of text (can be any form, such as sentence, paragraph, or a whole document). This means that a model predicts every word at a time based on prior generations and observations.

During training an LM, researchers give the LM a signal, telling the model whether the performed actions are good or not.
Here, we can find the similarity and analogy between an RL and an LM process. They both observe a state, make an action, and receive some feedback – although the feedback types are different.
RL
A method that you might think of quickly is to use a hand-crafted function to let the LM know whether their predicted text is good or not. This method can quickly get the generated sequence towards accumulating a highest reward we want.
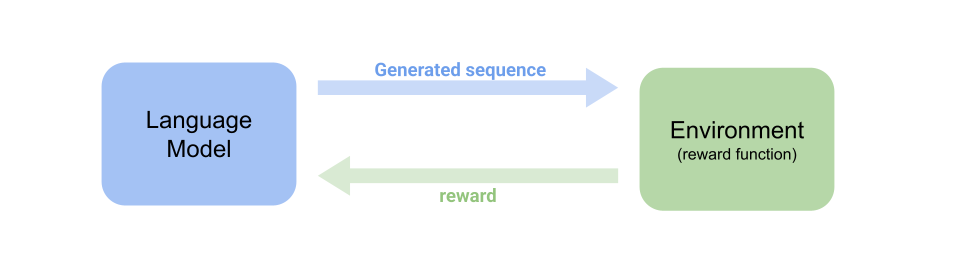
However, whether the human-designed reward is good is questionable, especially in an open-ended conversation. As you can imaging, there is rarely an absolutely correct response.
GAN
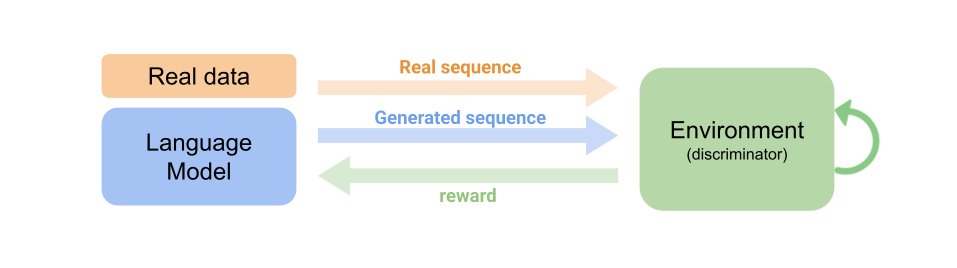
Therefore, people think of the generative adversarial networks, which is composed of a generator and a discriminator, by taking the LM as the generator and the discriminator as an online trained reward model. Specifically, the reward model is now continuing receiving the LM’s predictions as negative examples and human written responses as positive examples. The reward model is continuously updated to give the positive examples higher scores than the negative examples by batch.
 Curve icons created by Prosymbols Premium - Flaticon
Curve icons created by Prosymbols Premium - Flaticon
RLHF
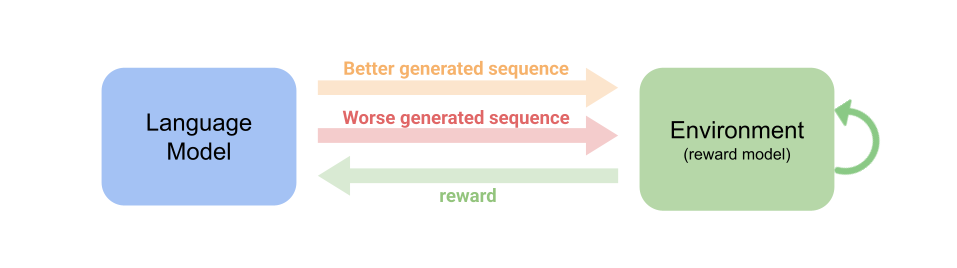
Using a reward model that learns to identify positive and negative examples can free us from designing crafted reward functions. However, it may not be so accurate since for different inputs we can expect the model will have bias on them. The reason can simply because some inputs show in the data more often. Also, sine the human written responses can already be learned by the LM, can be too far from the current LM’s policy, and can be too noisy. These two motivations lay down a foundation of RLHF. RLHF uses two LM generated responses and compare them pairwisely. This mitigates both the prior cons, but also raises a new problem that without a good foundation LM, the generated responses are both low quality and the algorithm will not work.
All of them, based on RL, suffer from the sample efficiency issues stemmed from the original RL algorithms. How do they compare to supervised learning (-similar) methods and how to improve the sample efficiency? Stay tune to updates on this article and further posts.